무엇가 글로 쓰는 것의 의미
요즘 업무 시간을 따져보면 개발보다 문서화를 더 열심히 하고 있다. 게다가 친절한 글쓰기를 위해 한 번 쓰고 넘기지 않고 독자가 이해할 수 있을지 확인하고 수정하는 iteration이 시간 오래 걸린다.
그래도 이게 써놓고나면 나한테도 유용하고 누군가에게 설명할 때도 편리하다. 특히 요즘 기억력이 매우 떨어지고 있어서 한 달 전 코드를 보면 ‘과거의 내가 굉장히 똑똑했구나’ 감탄하며 가져다 쓰곤 한다.
한편으론 왜 글을 이렇게 밖에 못 썼을까 아쉬운 마음도 든다. 시간은 오래 걸리는데 생각만큼 퀄리티가 안 나온다.
그래도 글을 쓰는 이유는 결국 글을 잘 써야만 한다는 목표의식도 있고, 글을 쓰면서 무형의 마음이 유형의 글로 정제되어 성장한다는 감각이 있기 때문이다. 누구에게나 blog를 만들고 어떤 글이라도 올려보는 건 도움이 되는 활동일 것이다.
요즘 드는 생각은 블로그에 일기처럼 짧은 일상 글을 쓰고 싶다. 막상 혼자 보는 일기는 지속하기가 어렵고, 막 보여주긴 또 그러니까 누군가 보는듯 마는듯한 이 공간이 좋을 것 같다. 그래서 이제 새로운 글에 알맞게 블로그를 개편해보려한다.
깔끔한 현재 레이아웃을 대체로 유지하되, 카테고리 구분이 쉬운 template로 교체해보자. 그리고 댓글 기능도 고려했는데 역시 안 넣는게 좋을 것 같다. 아직 관리 운영할 여력은 없는 것 같다. 나중에 생각하면 추가하는 게 좋을듯.
how-to
웹 개발에는 익숙치 않다보니 template 바꾸는 방법도 검색했지만 아주 친절한 문서는 찾지 못했다.
그래서 초보도 따라할 수 있는 jekyll theme 변경법을 남겨본다.
template 변경하면서 초보도 할 수 있는 몇가지 customizing 방법에 대해 남긴다.
그냥 template 파일을 덮어쓰니까 일단 작동은 한다… 거기에 몇가지 customize하면 충분할 것 같다.
사이드바에 카테고리 구분 추가
내가 쓰는 theme은 sidebar가 이미 구현되어 있다.
살펴보면 그냥 _includes/links-list.html 을 보라는 뜻이다.
<div class="sidebar well">
{% include links-list.html %\}
</div>
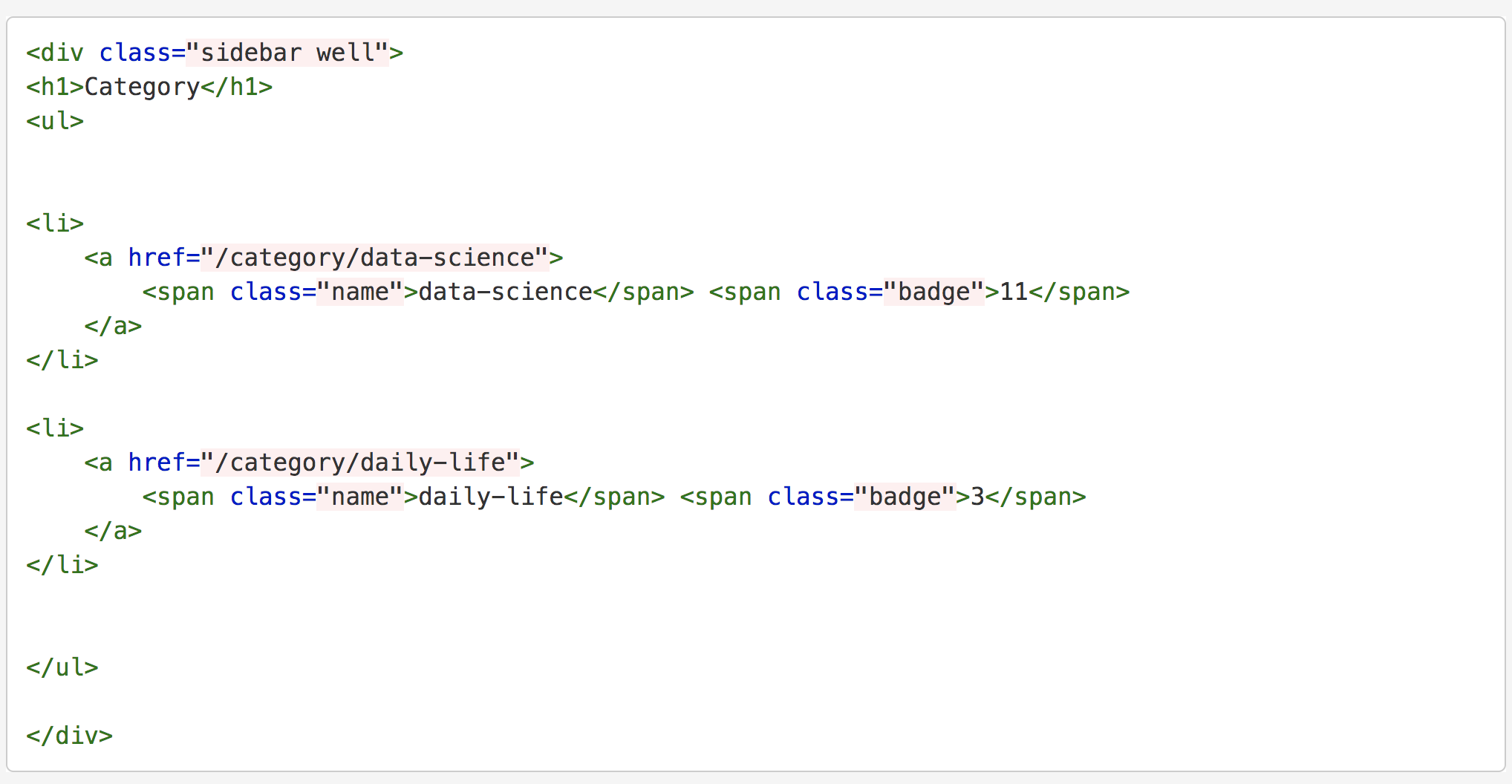
이 분이 쓰신 글을 참조하여 category를 화면에 뿌리는 것까지는 성공.
/_includes/links-list.html
<h1>Category</h1>
<ul>
{% for category in site.categories %}
<li>
<a href="{{ root_url }}/{{ site.category_dir }}{{ category | first }}">
<span class="name">{{ category | first }}</span> <span class="badge">{{ category | last | size }}</span>
</a>
</li>
{% endfor %}
</ul>

링크를 누르면 redirect 주소로 http://127.0.0.1:4000/category/data-science가 찍힌다.
이 글을 참조해 해당 주소 요청을 받아주는 파일을 만들자.
먼저 /category/data-science.md를 만든다.
---
layout: category
title: data-science
---
여기서 참조할 수 있게 /_layouts/category.html을 만든다.
layout: default로 css 입히고 a태그로 post 링크 잡는 정도의 기능만 있다.
중요한 건 markdown의 title로 category 구분한다는 점.
/category/*.md 파일 front matter에 title이 있어야 하는 이유다.
<div class="sidebar well">
{% assign category = page.title %}
<h1>{{category}}</h1>
<ul>
{% for post in site.categories[category] %}
<li>
<a href="{{ site.baseurl }}{{ post.url }}">
{{ post.title }}
</a>
<small>{{ post.date | date_to_string }}</small>
</li>
{% endfor %}
</ul>
</div>
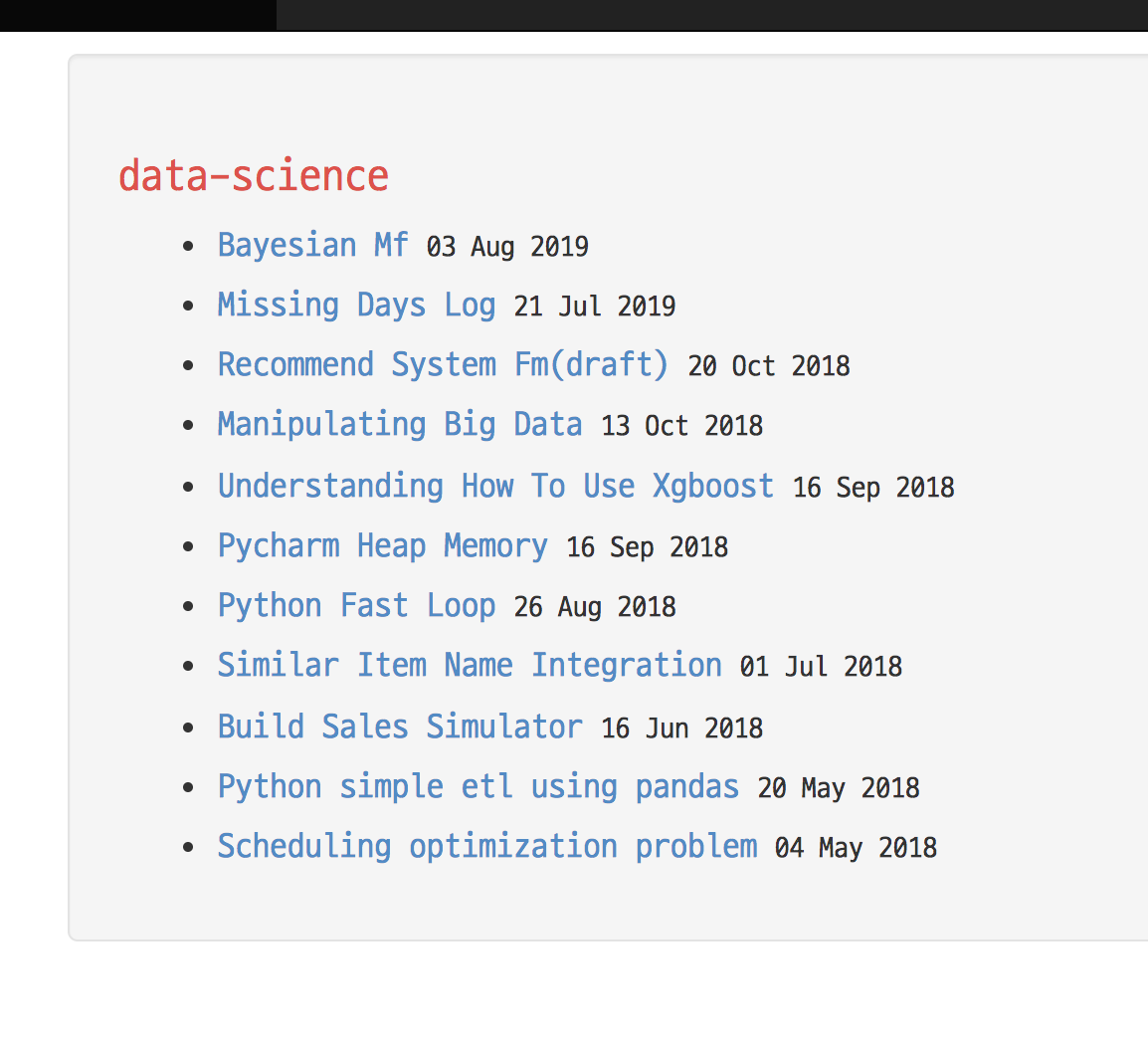
완성된 모습. 진짜 별 것도 아닌 화면이지만 성취감도 있고 좀 더 예뻤으면 하는 아쉬움도 들고 참 복잡하다. 이래서 웹개발 하시는 분들이 많은게 아닐까.
이미지가 div 박스를 뚫고 나온다
markdown으로 삽입한 이미지가 post의 div 박스보다 크게 나와서 당황했었는데
theme.css에서 img와 body 태그에 한 줄만 추가하면 된다.
img {
max-width: 100%;
}
body {
overflow: auto;
}
폰트 변경
d2coding.ttf 폰트 파일을 font 폴더에 저장한다음 theme.css에 추가했다.
@font-face {
font-family: "D2Coding";
src: url('/font/D2Coding.ttf') format('truetype');
}
body {
padding-top: 60px;
padding-bottom: 60px;
font-family: "D2Coding", menlo, consolas, courier, "courier new", fixed-width;
}
mathjax
블로그 글 따라 손쉽게 수식을 표현해주는 mathjax 기능을 넣었다.
나는 header.html의 head 태그 내부에 넣었는데 이 방식이 더 편한 것 같다.
{% if site.mathjax %}
<script type="text/x-mathjax-config">
MathJax.Hub.Config({tex2jax: {inlineMath: [['$','$'], ['\\(','\\)']]}});
</script>
<script type="text/javascript" src="https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/MathJax.js?config=TeX-AMS-MML_HTMLorMML"></script>
{% endif %}
그리고 site.mathjax를 받아주는 _config.yml 부분을 추가했다.
mathjax: true
역시 cdn을 쓰니까 굉장히 편리하다.
code block coloring
code block의 coloring이 예쁘지도 않고 빨간 음영이 눈에 띈다.
변경 방법을 찾아보니 /css/syntax.css 파일을 바꾸면 끝이다.
할 일은 좋은 소스를 찾기만 하면 된다.
preview page에서 theme를 고르고
동일한 github으로 소스를 가져온다.
여기에 배경색을 설정하려면 .highlight,pre.highlight{background: #ffffff;}를 추가한다.
나는 github 테마를 골랐는데 이름 때문에 언젠가 한 번 써보고 싶었다. IDE도 dark theme만 쓰다보니 못 썼지만 드디어 써보는구나.
웹 최상단 icon 추가
명칭이 favicon인 걸 처음 알았다. 기본값은 지구본 모양으로 나오는데 다수의 git blog가 지구본 아이콘을 그대로 쓰고 있다.
그래도 내 관점에서는 즐겨찾기에서 보이는 수많은 지구본 아이콘이 참 불편하다.
방법은 참 간단하다.
favicon 파일을 가져와 저장하고 header.html의 head 태그 내부에 한 줄만 추가하면 된다.
<link rel="icon" type="image/png" href="/favicon.png">
거의 blog 공사가 끝나간다. 남은 건 뭔지 기억이 잘 안 나지만 google에 등록하는 절차가 있던 것 같다. 거기에 네이버 robot도 긁어갈 수 있게 설정을 추가로 해보려한다.
P.S. 계속 windows 장비로 하다가 macbook을 쓰니 jekyll 쓰기도 편리하고 pycharm도 빠릿빠릿 돈다. 장비빨 덕에 더 좋은 글도 나올듯.