데이터 사이언스 강의를 들으려는 찰나에 질문을 받아서 어쩔 수 없이 다시 공부한 회귀분석
이번주에는 반드시 데이터 사이언스 인강를 듣고 정리 포스팅을 올리려 했는데, 카카오톡을 보니 동생이 회귀분석 질문을 보낸게 아닌가.
다행히 회귀분석은 첫 전공수업이어서 굉장히 열심히 했던 추억이 있다. 그래도 막상 보니 생각이 안 나는게 많아 다시 공부하며 시간을 보냈다.
그래서 결국 강의 요약은 또 다음 주로…😢 오늘 공부한 내용을 정리해본다.
문제
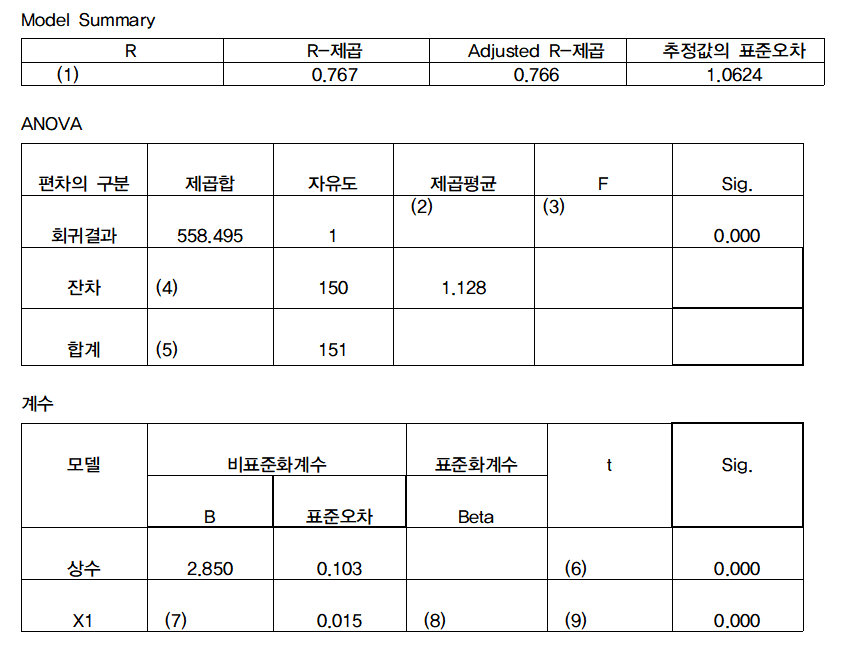
학부 때 시험 문제로 자주 나올만큼 의미있는 문제다. 하지만 알아도 쓸모가 없는 문제라고 생각하기 때문에 이런 건 괴롭지 않게 적당히 좀 내줬으면 좋겠다.
너무 쉬운 2, 4, 5는 생략하고 1번은 피처가 1개인 단순회귀에서 특징으로 $R^2$가 $correlation(x, y)^2$ 라는 점을 이용한다.
3번은 f분포의 특성인 분산의 비율을 구하라는 것이다. 자세히는 몰라 설명은 어렵다. (다음엔 이걸로 공부해서 올리는 걸로) 정답은 제곱평균의 비율로 (2)/1.128.
6, 9번은 t 통계량으로 $\frac{coef - 0}{s.e.}=\frac{2.850-0}{0.103}$ (왜 t 통계량을 쓰는 지는 링크참조)
대망의 7번은 숨은 그림 찾기하듯 풀어야된다. $\beta = \frac {\sum (x-\bar{x}) (y-\bar{y})} {\sum (x-\bar{x})^2}$ 이기 때문에
핵심은 $\sum (x-\bar{x}) (y-\bar{y})$ 와 $\sum (x-\bar{x})^2$ 를 어디서 찾을 것이냐다.
결론만 말하면 $\sum (x-\bar{x})^2$는 $\sigma^2$에서, $\sum { (x-\bar{x}) (y-\bar{y}) }$는 $r$에서 찾아야 된다.
코드로 상세 설명을 대신한다.
n = 152
n1 = 151
sigma = 1.0624
sigma2 = sigma ** 2
standard_error_beta = .015
sse = 1.128 * 150
syy = sse + 558.495
# sxx = sum of square (x - xbar)
# sxy = sum of (x - xbar)(y - ybar)
# standard_error_beta == (1.128 / sxx) ** .5
sxx = 1.128 / (standard_error_beta ** 2)
vx = sxx / n1
vy = syy / n1
r2 = .767
# r2 = sxy2 / sxx syy
sxy2 = r2 * sxx * syy
sxy = sxy2 ** .5
beta = sxy / sxx
print(beta)
상관계수와 회귀계수의 관계
내가 답을 처음에 준게 0.0002로 아주 작은 수였다. 코드를 잘못짜서 나온 값이었고 지금은 0.33이 나오지만 어찌됐건 이런 질문을 했다.
상관계수가 0.85가 넘는데 회기계수가 그렇게 작을수가 있냐고.
사실 수식만 보면 알 수 있는데 답은 yes다. x의 분산이 y보다 크면 $\beta$ 값이 작아져서 0처럼 보일 수 있다.
예시를 만들어서 해보니 정말로 그렇다.
import random
import numpy as np
n = 150
samples = np.array([[random.uniform(10, 20) for i in range(n)],
[random.uniform(10, 20) for i in range(n)]]).T
correlation_matrix = np.array([[1, .99], [.99, 1]])
samples = samples @ np.linalg.cholesky(correlation_matrix) @ np.linalg.cholesky(correlation_matrix) \
@ np.linalg.cholesky(correlation_matrix)
x = samples[:, 0]
y = samples[:, 1]
corr = lambda x, y: np.corrcoef(x, y)[0, 1]
print('corr: ', corr(x, y))
covmat = np.cov(x, y)
vx = covmat[0, 0]
vy = covmat[1, 1]
sx = vx ** .5
sy = vy ** .5
slope1 = (np.cov(x, y)[0, 1] / vx)
slope2 = (corr(x, y) * sy / sx)
from sklearn import linear_model
mdl = linear_model.LinearRegression().fit(x.reshape(-1, 1), y)
slope3 = mdl.coef_[0]
print('slope: ',slope1)
상관계수는 0.7491인데 회귀계수는 0.001이 나올 것이다.
그렇다고 이 계수가 꼭 버려지지는 않는게, 숫자가 작은 만큼 오차도 작아 회귀계수에 대한 t 검정이 유의하다고 나올 수 있다.
새삼스레 다시 느끼지만 회귀분석도 깊이 들어가면 한도 끝도 없이 어려워진다.